クローラーとは?仕組みやサイト制作時の重要性を解説

クローラーとはインターネット(Web)上を周回するプログラムです。他にも、「ボット(Bot)」「スパイダー」「ロボット」などと呼ばています。クローラーはWeb上に存在するサイトや文章、画像などの情報を自動で取得し、検索エンジンのインデックスを作成します。
今回は、クローラーの基本、クローラー巡回のチェック、申請方法などをまとめましたので、ご活用ください。
この記事の目次
クローラーとは
クローラーは検索エンジン運営側に管理されているため、検索エンジンごとにクローラーの種類があります。以下は代表例です。
- Googlebot:「Google」のクローラー
- Bingbot(マイクロソフト・Bing):マイクロソフト「Bing」のクローラー
- Baidspider:中国の検索エンジン「Baidu」のクローラー
これらのクローラーが巡回してコンテンツの情報を収集・登録することを「クローリング」といいます。
クローリングの対象
クローラーがサイトをクローリングする際に対象となるファイルには、以下のようにさまざまな種類があります。
- HTMLファイル
- CSSファイル
- JavaScriptファイル
- 動画
- 画像
- オフィス文書(Word/Excel/PowerPoint)
- Flash
クローラーは、サーバーとの間で通信してクローリングしており、「HTTP/HTTPSプロトコル(通信規約)」というものが通信手段です。
「HTTP/HTTPSプロトコル(通信規約)」とは、サイト住所を表すURLの共通の通信規約 です。表示を省略される場合がありますが、URLが「http(暗号化されていない通信)」や「https(暗号化された通信)」で始まっているのはそのためです。スマホやパソコンなどユーザーのインターネット環境が違っていても、同じようにデータをやり取りできるよう定められたものなのです。
クローラーは、「HTTP/HTTPSプロトコル」の形で取得できる情報をすべてクローリングの対象としています。
HTTPとHTTPSの違いについてはこちらの記事を参照
・httpとhttpsの違いとは?覚えておきたいWebの知識
代表的なクローラー
クローラーは大きく2種類に分類して考えられることが多いでしょう。
①Googleのクローラー(Googlebot)
②その他のクローラー
- Bingbot:マイクロソフトが運営する「Bing」のクローラー
- Baiduspider:中国最大の検索エンジン「Baidu」のクローラー
Googleとその他で大別される理由は、Googleが世界40カ国においてトップシェアの検索エンジンだからです。Googleの検索エンジンのシェア率は日本だけでみてもPC79%、モバイル75%以上を誇っており、さらに日本のYahoo!の検索エンジンにもGoogleの検索エンジンが採用されています。
そのため、日本国内でSEOを攻略していくためにはGoogleのクローラー(Googlebot)を意識した対策ができれば良い、といっても過言ではありません。
クローラーの仕組み
クローラーはどのような仕組みで動くプログラムなのか、詳しく見ていきましょう。
クローリングによってインデックス登録されて、検索順位が決定します。インデックス登録されて、検索エンジンに登録済みになった後も内部にリンクを発見する度、リンク先のWebサイトにアクセスして解析・登録していくという工程を繰り返し行っているのです。
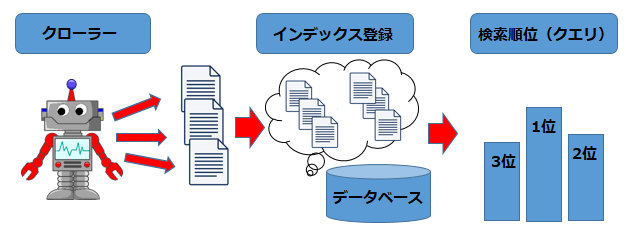
クローリング
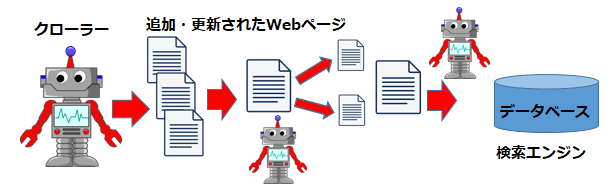
クローリングとは、Googleなどの検索エンジンのクローラーがインターネット上に存在するWebサイトなどのリンクを辿り、ページ情報を取得することを指します。
クローラーは定期的にインターネット上を巡回して新たな情報をクローリングします。クローラーによって取得された情報は、検索エンジンの運営側によってWeb上に公開したり、検索結果の順位に影響を与えたりします。その結果としてインターネット利用者は、新しいWebサイトや更新されたページの情報を閲覧することが可能になります。
インデックス登録
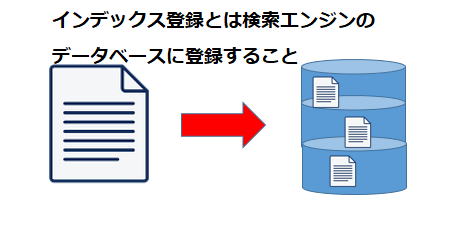
インデックス登録とは、クローラーが定期的にクローリングして得た情報を検索エンジンのデータベースに保存して格納することを指します。
検索エンジンのデータベースに格納(インデックス登録)されることで、初めてインターネット利用者がWebサイトやページを検索結果として閲覧することができるようになるのです。
検索順位決定
検索順位はクローリングされた情報が検索エンジンのデータベースにインデックス登録された後に、検索エンジンが定めたアルゴリズムに従って決まります。各検索エンジンのアルゴリズムにもよりますが、Googleの検索エンジンのアルゴリズムは200以上も存在し、日々アップデートされています。アップデートされるアルゴリズムを検索順位に反映するために、クローラーは重要な役割を果たしているといえるでしょう。
Webサイト制作時のクローラーの重要性
冒頭でもお伝えしましたが、SEOを実施していく上でクローリングされることは必須の条件です。「クローラーに読み取ってもらいやすいWebサイトづくり」が大切になってきます。
クローラーの巡回しやすさを表す「クローラビリティ」を理解することは一見エンジニア向けの内容かもしれませんが、ブログや自社コンテンツを更新している人にも関わることなので、意識的にチェックしましょう。
検索エンジン運営側の企業にとって検索エンジンはサービスの一つですから、多くのユーザーに利用されることを目指しています。自社の検索エンジンをユーザーに利用してもらうために、価値ある情報を正しい順番で表示することが重要なので、クローラーの存在は必須なのです。
そして、Webサイト制作者・運営者にとっても自社サイトを検索結果に上位表示し、サイトにアクセスしてもらう等の目的があるため、クローラーにクローリングしてもらうことが重要になります。
クローラーがなければWebサイトやページを作っても検索結果に表示されず、検索流入によるアクセスが得られません。
クローラビリティ向上の秘訣
それでは、WEBサイトを運営・管理していくなかでクローラビリティを向上させるための秘訣を以下で詳しくご紹介します。
クロールリクエストを送る
クロールリクエストは、クローラーに新たに制作したWebサイトやページを巡回してもらい、インデックス登録を促進する方法です。
Googleサーチコンソールを使うことで、検索エンジンに対してクロールリクエストを送ることができます。なお、既にインデックス登録済みのWebサイトやページを更新した場合にも有効的です。
パンくずリスト(breadcrumb list)を設定する
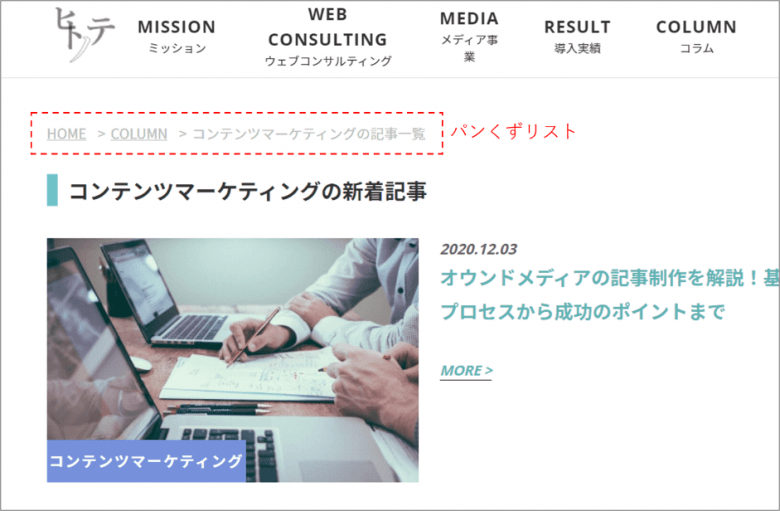
「パンくずリスト」とは、現在閲覧しているWEBページの位置をわかりやすくしたもので、WEBサイトの左上などにあるトップページからの階層順を表したリンクを指します。
各ページにパンくずリストを設置するとリンク数が増えて回遊率が向上するうえ、ページ間の親子関係も明確になることでより正確な情報をクローラーに伝えることができます。
詳細はこちら!
・パンくずリストはSEOに効果アリ!作り方と気を付けるポイントをご紹介
重要なコンテンツを浅い階層に設置する
Webサイトにとって重要なページほどなるべくトップページから浅い階層に設置した方が、クローラーが巡回しやすいです。重要なページに辿り着くまでに何ページも巡回しなくてはならない場合、インデックス登録にも時間がかかり、検索結果に表示されたり、検索順位が上がるにも時間がかかるでしょう。
内部リンクを設置する
繰り返しになりますが、クローラーはサイト内部のリンクを把握しアクセスすることで新たなページを発見するため、内部リンクがあるとそのサイトからクローラーが巡回しやすくなります。コンテンツ制作時などに関連性の高いテーマが出てきた場合は、積極的にリンクを貼るようにしましょう。
注意したいのは、闇雲にリンクを貼ってしまわないということです。Googleは関連性の高いリンクほど評価します。それは逆も然りで、関連性が低いと判断されてしまえば低評価を受け検索順位を獲得することが難しくなってしまうということも頭に入れておきましょう。
外部リンクを貼ってもらう
これは、自社とは異なるページに自社サイトのリンクを貼ってもらうという方法です。例えば、「ここのスイーツが美味しかった」と誰かが自社サイトのURLを貼り付けたとしたならば、これが外部リンクに当てはまります。
より関連性と評価の高いサイトから外部リンクを貼ってもらうことは評価に直結しますが、質の低いサイトから外部リンクを貼られても、評価が上がらないどころかペナルティを受けるリスクもあるため注意が必要です。
詳細はこちら!
被リンクとは?メリットや確認方法、無料・有料の被リンクチェックツールも紹介
重複コンテンツを無くす(URLの正規化)
重複コンテンツとは、コンテンツの内容が他のページ(同ドメインまたは別ドメイン)の内容と重複していることを指します。
例えば、以下の場合が当てはまります。
- 他のページコンテンツまたは別サイトのコンテンツと全く同じである(ミラーページ)
- 他のページコンテンツまたは別サイトのコンテンツと極めて似ている など
重複コンテンツやページによっては致し方ない場合が存在するため、全てが「悪」というわけではありません。ただ、異なるURLでまったく同じコンテンツがあるというのは、クローラーからしてもわかりにくいものです。本来評価されるべきページが評価され辛くなったり、検索結果の適した順位に反映されなかったりというSEOへの悪影響も引き起こしかねません。
また、幅広い内容のコンテンツを検索結果に表示させようとする動きがあるため、ペナルティが課されなかった場合でも似た情報は表示され辛くなる可能性があります。リスクを減らす意味でも重複コンテンツのチェックを怠らず、できるだけ無くすように心がけましょう。
以下では、ツールの紹介とURL正規化の方法を解説しています。
重複コンテンツを確認、診断できるツール
①Googleサーチコンソールのカバレッジで除外をクリック
googleサーチコンソールは一部重複の場合は表示されず、全く同じページが複数ある完全コピーコンテンツの場合のみ表示されるので注意が必要。「URL検査」を実施できる。
②Google検索
Google検索結果URLの末尾に
&filter=0
と入力すると意図的に検索結果に表示されなかったページを確認できる
③sujiko.jp
sujiko.jpは、重複の可能性があるコンテンツがわかっているときにその両者を比較できる
④Copy Content Detector
Copy Content Detectorは、アップ前のコンテンツをチェックしたいときに便利
URLの正規化の方法
①極力消去して1つに絞る
- URLや同じページに「www.」が含まれているものと含まれていないものが存在し、複数のURLからアクセスできるケース
- 「https;//sample.com/」と「https;//sample.com/index.html」どちらのURLを入力してもトップにアクセスできるケース
上記に加え、「自動で生成されるページ」も該当してしまうので、定期的な確認を行うことでURLを1つに絞るようにしましょう。
②Canonicalタグ
デバイスごとにURLが異なるときなど、どちらのURLも必要で1つをオリジナルとして正規化したいときに使う方法です。
正規化したいページ以外のheadタグ内に
link rel=”canonical” href=”https://example.com/category/page” /
と記載することでどのページが正規かを指定しましょう。
HTTPステータスコードを適切に設定する
ステータスコードの設定を間違えてしまうと
- セッション数の減少
- 検索結果の順位下落
といった悪影響を引き起こし、Googleサーチコンソールでエラーが発生する場合があります。
ステータスコードの設定は、サイト運営の要とも言える作業ですので、問題がないか不安に思われる場合は専門とする会社に相談してみるのがいいかもしれません。
リンクはなるべくテキストリンクにする
リンクをテキストリンクにすることで、クローラーはアンカーテキストからページ情報を読み取ることができます。テキストリンク(アンカーテキスト)とは、URLのリンクが埋め込まれた文字列を指し、HTMLの仕組みで構成されています。本記事でも参考サイトを挙げる時にいくつか登場していますよね。
例えば、
↓【2023年版】SEO対策とは?仕組みや施策、進め方などを徹底解説↓
https://hitonote.co.jp/wp2/column/seo/259/
というように、無駄な要素を盛り込んで長ったらしく記載するよりも、
というシンプルな表記でリンクへ飛べる方が分かりやすく、ゴチャゴチャもしませんよね。こういった小さな想いやりがユーザーの読みやすさや離脱率低下に繋がり、ユーザビリティ向上の1歩にもなるのです。
短く簡潔なテキストにして効果的にリンクテキストを記述することをGoogle自身が推奨しています。アンカーテキストにSEOで対策しているキーワードを入れることも重要です。
・SEOにおいて重要なアンカーテキストとは?実装時に抑えるべきポイントを解説
robots.txtのDisallow記述に気をつける
robots.txtは、サイトに対するクローラの巡回を制御するためのファイルで、特定URLへの巡回を阻止するなど便利な機能があります。
巡回を拒否するページのURLパスやURLパスの先頭部分を指定できる「Disallow」で記述した場合は、サイト全体のクローリングをブロックすることが可能です。そのため、誤って記述してしまうと検索結果に表示されなくなってしまいますので、注意しましょう。
また、Disallowではクローラーの巡回をブロックすることができていても、インデックス登録される可能性があります。Googleのサポートにも“ブロック対象の URL がウェブ上の他の場所からリンクされている場合、その URL を検出してインデックスに登録する可能性があります。”という記載があります。
Disallowではインデックス登録を完全に禁止できるわけではないということも覚えておきましょう。すでにDisallowで記述してしまっているサイトのインデックスを制御するためには、「noindexメタタグ」でインデックス自体を禁止する必要があります。
サイト構造を簡潔にする
サイト構造を簡潔にすることも重要です。一般的にトップページから2クリックですべてのページに辿り着ける構造が理想とされています。それは、クローラーは必ずしも全てのページを巡回するわけではないというのが大きな理由です。
何度もリンクを踏まなければたどり着けないページはクローラーにとっても探しにくいと同時に、後になるにつれてクローリングされる確率が薄くなります。
複雑にカテゴライズされすぎていないかサイト構造を見直し、クローラーが効率的に巡回できるようわかりやすい構造を意識して制作しましょう。
クローリングしてほしくない場合
クローラーにWEBサイトを巡回されたページは良くも悪くも検索エンジンに登録され、コンテンツの質に応じた評価を受けます。WEBサイトを運営していくと、どうしても事業サービス的には不可欠だが、SEOにおいては不利なページというものができてきます。
それに代表されるページが以下のもので、必要に応じてクローラーが巡回されないように設定しましょう。
- お問い合わせ&サンクス:コンテンツ内容が少ない
- 会員限定ページ:ログインしないと閲覧できない場合が多く、クローラーが読み込めない
- 画像だらけのLP:コンテンツが少ない or キャンペーン用にコピー複製している場合がある
- テスト開発中のページ:テスト段階なのでインデックスされて見られては困る
これらのページはどうしてもコンテンツ内容が少なくなり、また品質も低くなりがちで低評価を受けてしまうかもしれません。クローラー巡回の散開を防ぎ重要なページを優先的にクローリングしてもらうためにも、クローラー巡回をブロックする必要があります。
「robots.txt」を使用する
クローラーを効率よく巡回させるために一部のWEBページをブロックしたいときはrobots.txtを使うとよいでしょう。robots.txtとは、クローラーに対してWEBサイト情報の収集に制御をかけることができるファイルの事を指します。
robots.txtでクロールをしてほしくないページを制御すれば、クロールしてほしいページだけを優先的にクロールさせることが可能になります。
詳細はこちら!
・【robots.txt】基礎から安心の徹底解説
HTMLファイルに「noindex」と記述
クローラーにWebサイトやページをクローリングされたくない場合はHTMLファイルのメタ情報に「noindex」と記述することでインデックス登録されないようにできます。
noindexとは、検索エンジンのクローラーの動作を制御するための指示です。noindexをHTMLファイルのメタ情報に追加すると該当するサイトやページの収集や索引されないようにしてくれます。
WordPressで構築されたサイトの場合、使用のテーマにもよりますがページ投稿画面の下部などに「この固定ページ/投稿に noindexを使用する」や「インデックスしない(noindex)」というチェック項目があります。
これらをチェックすると簡単に該当ページのクローリングを防ぐことができますが、「noindex」のみではインデックスされないというだけでクローラーが巡回することに変わりはありません。そのため、完全にクローリングを防ぐためには「noindex」に加えて「robots.txt」で巡回を拒否するというのが理想的です。
「Basic認証」や「IPアドレス」でアクセスを制限
上記の方法で、気をつけたい点として「robots.txt」と「noindex」のどちらも、一般ユーザーのアクセスが可能になっていることがあげられます。一般のユーザーに見られたくないときは、「Basic認証」や「IPアドレス」でアクセスの制限を設定するようにしましょう。
クローラー巡回のチェック方法
クローラーが自社サイトに巡回しているか調べられたら便利ですよね。サイト管理者がクローラーの巡回状況を確認するにするには「site: 検索」と「Googleサーチコンソール」を使用した方法があります。
Googleで「site:ドメイン名」検索する
例えば、新規ページ「example.com」を公開してクローラーが巡回したか知りたい場合、「site:example.com」と検索して検索結果画面に表示されればクローラーにインデックスされているということになります。
Googleサーチコンソールを利用する
「Googleサーチコンソール」とはGoogleが提供する無料のツールです。サーチコンソールにログインして、URL検査という項目から調べたいサイトのURLを貼り付けると、インデックス登録(クローラー巡回)を調べられます。
サーチコンソールの使い方はこちら
・サーチコンソールの使い方からサイト改善方法までを解説!基本から応用まで
クローラー巡回の申請方法
新しいWEBサイトやページを更新したら、クローラーに巡回の申請を行いましょう。主な申請方法は「Googleにサイトマップを提供する」、「URL検査ツール(元Fetch as Google)を使用する」の2種類です。どちらもGoogleサーチコンソールを使用します。
Googleにサイトマップを提供する
- Googleサーチコンソールにログイン
- メニューのインデックスからサイトマップをクリック
- 「新しいサイトマップの追加」の入力欄に、別途作成したサイトマップファイル(sitemap.xml)のURLを記述
- 送信ボタンを押して完了
URL検査ツールを使用する
- Googleサーチコンソールにログイン
- メニューのURL検査をクリック
- クローラーに巡回してほしいページのURLを入力し、Enter
- 検査結果画面に「インデックス登録をリクエスト」が表示されるので、クリックして完了
まとめ
クローラーとはインターネット(WEB)上に存在するサイトや文章、画像などの情報を周期的に取得し、自動で検索結果に影響するデータベースを作成するプログラムです。
クローラーはリンクをたどり、WEBサイトを巡回するため、自社サイトのリンク管理が大切になります。新しくサイトを作成したり、ページを更新したりする場合はクローラーに巡回申請をして検索エンジンへの登録をリクエストしましょう。 クローラーの仕組みをしっかりと理解して、WEBサイト運営に役立ててください。
関連記事はこちら
・Googleサジェストの仕組みを理解しよう!サジェスト汚染の解決法も解説!
・robots.txtとは?基礎から記述・活用方法まで押さえた徹底解説!
・canonicalとは?正しく使い方を理解してSEOを強化しよう!
・SEOにおいて重要なheadタグの書き方 タイトル、カノニカルetc
執筆者:ヒトノート編集部
株式会社ヒトノテのオウンドメディア、WEBマーケティングの学習帳「ヒトノート -Hito note-」の編集部。

監修者:坪昌史
株式会社ヒトノテの代表取締役CEO。 エンジニアとしてキャリアスタートし、サイバーエージェントのSEO分析研究機関を経て、リクルートの横断マーケティング組織のマネージャー&全社SEO技術責任者を務める。その後、独立しSEOを中心としたクライアントの課題解決を行う。2017年、株式会社ヒトノテを創業し、様々な企業のウェブマーケティングの支援を行う。
おすすめの関連記事
 2020年3月17日 【プレスリリース】日本の伝統メディア「ワゴコロ」が月間16万PVを突破 Posted in お知らせ
2020年3月17日 【プレスリリース】日本の伝統メディア「ワゴコロ」が月間16万PVを突破 Posted in お知らせ 2024年7月2日 一覧ページの内部リンクはどうすればいいの?SEOで必要なリンクと設置の工夫を考察 Posted in SEO
2024年7月2日 一覧ページの内部リンクはどうすればいいの?SEOで必要なリンクと設置の工夫を考察 Posted in SEO 2024年9月24日 SEOで複数のキーワードを1ページで対策してよいのか? Posted in SEO
2024年9月24日 SEOで複数のキーワードを1ページで対策してよいのか? Posted in SEO 2020年6月2日 リンク切れチェックツールおすすめ5選!一括・効率的にリンク切れを対策しよう Posted in サイト改善 / 制作
2020年6月2日 リンク切れチェックツールおすすめ5選!一括・効率的にリンク切れを対策しよう Posted in サイト改善 / 制作 2020年4月14日 代表坪が「Schoo(スクー)」の動画講座に登壇しました Posted in お知らせ
2020年4月14日 代表坪が「Schoo(スクー)」の動画講座に登壇しました Posted in お知らせ 2022年12月2日 GA4とUAの併用方法を紹介!GA4とUAの比較や併用のメリットを解説 Posted in アクセス解析
2022年12月2日 GA4とUAの併用方法を紹介!GA4とUAの比較や併用のメリットを解説 Posted in アクセス解析 2019年11月29日 株式会社転職picks様の「転職picksサイト」構築とコンテンツ記事制作実績 Posted in 導入実績
2019年11月29日 株式会社転職picks様の「転職picksサイト」構築とコンテンツ記事制作実績 Posted in 導入実績 2023年9月27日 【比較一覧】おすすめのSEO会社13選!3つの選定ポイントも解説 Posted in SEO, コラム
2023年9月27日 【比較一覧】おすすめのSEO会社13選!3つの選定ポイントも解説 Posted in SEO, コラム
─ 記事カテゴリから探す ─

元リクルートのSEO責任者へ無料相談
人気記事ランキング
-

2024.05.30
キーワードマーケティングのやり方とは?SEOの効果が見込める手順を徹底解説
-

2024.05.27
SEOにおけるURL設計のベストプラクティス
-

2024.04.25
ページネーションのSEOにおけるベストプラクティス
-

2024.04.22
E-E-A-Tとは?Googleが評価するコンテンツの基準や対策を解説
-

2021.07.09
Webコンテンツにおける正しい引用の書き方をマスターしよう!
-

2021.12.06
レスポンシブデザインの最適ブレイクポイントとは?メディアクエリの書き方も解説
-

2021.12.22
【徹底比較】さくらのクラウドとAWSの特徴・機能・料金の違いを解説
-
2022.02.21
「note」のユーザー数や年齢層を徹底分析!【2022年版】
-

2022.07.05
WordPressで301リダイレクトを設定する方法とは?初心者でも可能








