構造化データとは?マークアップを行うメリットやSEOへの影響を解説

構造化データとは、検索エンジンがページ内の情報を認識できるようにするデータ形式のことです。構造化データを設定することで、検索結果に画像やレビューなどのリッチリザルトが表示されるようになります。
しかし、サイトによって設定できる構造化データが異なるため、導入には専門知識が必要です。また、設定した内容を確認するツールの使い方も知っておく必要があります。
本記事では、構造化データの役割やメリット、SEOへの影響を紹介します。さらに、構造化データの設定方法や検証ツールなどの実践的な内容も解説します。
この記事の目次
構造化データの役割とは?
構造化データには、主に2つの役割があります。
・検索エンジンがページの内容を理解できるようにする
・検索結果にさまざまな要素を表示する
Webページは人間が読みやすいように表示されていますが、検索エンジンが人間と同じようにテキストを読み取ることはできません。
そのため検索エンジンに理解してもらうためには、コンピュータシステムが読み取れる形式でテキストの意味を記述する必要があります。
このとき、ルールに従った「タグ」を記述して検索エンジンに文書の構造を伝える(マークアップする)データ形式のことを「構造化データ」と呼びます。
<div>
会社名:株式会社ヒトノテ
所在地:東京都千代田区
</div>上記のような場合、以前は「株式会社ヒトノテ」という文字列を会社の名前だと判断することが困難でした。しかし現在は、下記のようにマークアップすることで「株式会社ヒトノテ」は社名、「東京都千代田区」は所在地だと理解させることが可能になりました。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "株式会社ヒトノテ",
"address": {
"@type": "PostalAddress",
"addressLocality": "千代田区, 東京",
}
} </script>このような「文脈や背景まで解釈・処理して蓄積しよう」という考え方を「セマンティックWeb」と呼びます。そして構造化データは、セマンティックWebの考え方に基づいて生まれました。
また、検索エンジンが文脈や背景まで解釈できるようになったことで、それらの情報を活用して検索結果にさまざまな要素を表示できるようになりました。たとえば検索結果の「リッチリザルト」や「強調スニペット」も構造化データ活用の応用例として知られています。
セマンティックWebとは?
セマンティックWebとは、統一された形式に基づいてデータを記載することで、コンピュータシステムも読み込みやすいWebページにしようという取り組みのことです。
WebページのHTMLは、人間がブラウザで読めるようにデータを成形するためのものであり、データの種類や所在などの記述がメインです。一方でソフトウェアが読み取れるデータは不足しており、ページを横断するようなデータ取得などには向いていません。そこで推進されたのがセマンティックWebです。
統一的なXMLで作成したページに「タグ」と呼ばれる値を用いることで、コンピュータが情報を自動的に解釈・処理できるようになりました。現在では、強調スニペットなどの応用された実装例も広く知られています。
構造化データを設定するメリット
構造化データを設定することで、以下の2つのメリットが得られます。
・検索エンジンがサイト内のコンテンツを理解しやすくなる
・検索結果にリッチリザルトが表示される
むやみに構造化データを導入するのではなく、メリットを含めて本質的に理解したうえで取り組むことでより効率的に活用が可能です。
ここからは2つのメリットについて画像を用いてわかりやすく解説します。
検索エンジンがサイト内のコンテンツを理解しやすくなる
前述のように、構造化データを活用することで検索エンジンがサイト内のコンテンツを正しく理解できるようになります。サイト内のテキストや画像がどのような情報なのかが適切に認識されるため、コンテンツに適した検索結果に表示される可能性が高まるでしょう。
たとえばコンテンツ内に「株式会社ヒトノテ」「千代田区」「Webコンサルティング事業」など情報があっても、マークアップされていないとそれぞれが単なる文字列として認識されてしまう可能性があります。一方でマークアップされていれば、「株式会社ヒトノテは千代田区にあるWebコンサルティング事業会社で…」のように明確かつ詳細に検索エンジンに理解させることが可能です。
また、同音異義語がある場合であっても、明確に意味を記述しておけば正しい意味で認識されます。
検索結果にリッチリザルトが表示される
構造化データによって情報の持つ意味を検索エンジンに適切に伝えることで、その情報を活用したさまざまな要素が検索結果に表示されるようになります。
下の画像のような「リッチリザルト」は、見たことのある方が多いのではないでしょうか。
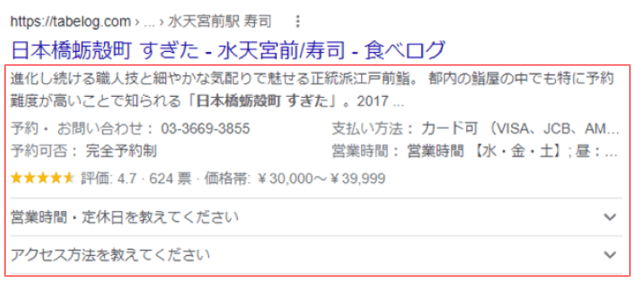
通常の検索結果では、青色のリンク(ページタイトル)の下に「meta description」や「サイト内テキスト」などから引用されたページの説明テキストが表示されます。しかし構造化データが活用されたページでは、リンクの下に追加情報が表示されることがあります。
画像の例では、店名に加えてレビューや価格などの情報が表示されており、リンクを開く前のユーザーに対しても店舗・サービスの情報をアピール可能です。
このように構造化データで情報の意味を明確にして視覚的な検索結果を表示させることで、競合サイトと差別化できます。また、デバイスのスクリーンの占有率も高まるため、クリック率の向上も期待できます。
しかし、構造化データを用いたら必ずリッチリザルトが表示されるわけではありません。検索エンジンの構造化データに関するガイドラインに抵触していたり、検索キーワードとの関連性が低かったりする場合には、リッチリザルトが表示されないことがあります。
リッチリザルトと似た強調スニペットとは?
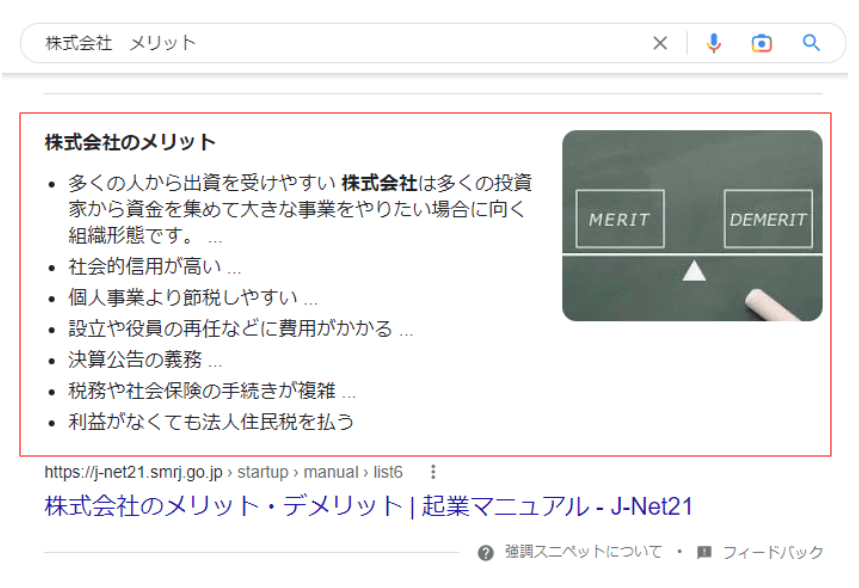
Googleの検索結果画面では、特定ページ内の情報を抜粋した「強調スニペット」が表示されることがあります。特に「〇〇とは」のような質問クエリを入力した際に表示されることが多いです。
Google検索ヘルプでは「強調スニペットが選ばれる仕組み」について以下のように記載しています。
あるページが特定の検索リクエストに対して強調表示するスニペットとして適しているかどうかを、自動システムで判断します。
引用:Google検索ヘルプ
選ばれるための明確な方法はないものの、自動システムで判別できる形式で記述する(構造化データを用いている)ことは重要なポイントといえます。
リッチリザルトと似た言葉のリッチスニペットとは?
リッチリザルトと似た「リッチスニペット」という言葉を聞いたことがある方も多いのではないでしょうか。実はリッチリザルトは、「リッチスニペット」「リッチカード」「エンリッチ検索結果」などの同じ意味の言葉が混在していた中で、Googleが正式に統一した名称です。そのため現在は、リッチリザルトという言葉を使用するのが適切です。
リッチリザルト
引用:Search Console ヘルプ
視覚的な機能や操作機能が追加された、Google検索結果です。以前は「リッチカード」または「リッチ スニペット」として知られていました。
構造化データを実装してメリットを享受するための課題
構造化データにはリッチリザルトの表示などのメリットがありますが、すべてのサイトに効果をもたらすとは限りません。
なぜなら構造化データの上手く活用するためには専門知識を必要とすることがあるからです。知らずに取り組むと余分な手間とコストがかかってしまうおそれがあるので注意しましょう。
ここでは構造化データを活用するために必要な知識について紹介します。把握したうえで、構造化データを導入するかどうか検討しましょう。
専門知識を必要とする
構造化データを活用することでリッチリザルトによる集客力アップなどが見込めます。しかし導入には専門知識が必要であり、場合によっては手間とコストに見合わないケースもあります。そのため、導入前に構造化データの活用に必要な専門知識を確認しておきましょう。
まずは構造化データの「形式(シンタックス)」の知識が必要です。Googleが推奨している「JSON-LD」に加えて「microdata」「RDFa」という形式もあり、形式によって記述方法も異なります。
次に、「schema.org」などの「ボキャブラリー(属性や属性値)」の知識が必要です。ボキャブラリーは日々拡張されているため、構造化データを実装するためには定期的に更新されるボキャブラリーへの対応が求められます。
ボキャブラリーとシンタックスだけでも多くの学習が必要であり、細かな技術の習得も必要です。そのため、構造化データがすべてのサイト運営者にメリットをもたらすとは限りません。
構造化データによるSEO効果
構造化データはSEOに直接的な影響を及ぼしません。GoogleのJohn Mueller氏も2017年のウェブマスター向けオフィスアワーで、構造化データを設定したことで順位が上がることはないと言及しました。
しかし、構造化データによって得られるメリットによる間接的なSEO効果は期待できます。とくに「クローラリビティ」と「クリック率」の向上によって、間接的にGoogleからの評価が高まる可能性は考えられるでしょう。
ここからは構造化データがSEOにもたらす間接的な効果について詳しく解説します。
クローラビリティの向上
構造化データをマークアップすることで、クローラリビティの向上が期待できます。クローラリビティとは、Web上の情報を収集するプログラム(クローラー)による見つけやすさや理解しやすさを示す言葉です。
Web上には無数のコンテンツがあり、クローラーは1日で数億ページを訪れているといわれています。多忙なクローラーにページを見つけてもらうためには、構造化データをマークアップして理解しやすいコンテンツに整えることが大切です。
構造化データを用いていないページよりも明確かつ詳細な情報をインデックスできるので、クローラリビティの向上が期待できます。クローラリビティが高まればページへの総合的な評価も高まり、検索順位の向上にもつながるでしょう。
クリック率の向上
構造化データを用いることでリッチリザルトが表示されることがあります。リッチリザルトでは、ページタイトルに加えて画像などのデータも表示されるため、ユーザーに与える視覚情報が増えます。検索結果画面の中でもとくに大きく表示されるので、クリック率を向上可能です。
クリック率をさらに高めるためには、Google検索がサポートする構造化データをマークアップして、リッチリザルトを効率的に活用しましょう。
- Article(ニュース記事など)
- パンくずリスト
- カルーセル
- Event(セミナーなど)
- Q&A など
また近年は、「〇〇とは」のような質問クエリに対する「強調スニペット」や「〇〇 求人」のような求人クエリに対する「Googleしごと検索」など、さまざまな応用機能が実装されています。今のうちに構造化データを導入しておくことで、将来的にさらなるメリットを得られるかもしれません。
構造化データを構成する2つの要素
構造化データは、「ボキャブラリー」と「シンタックス」の2つの要素で構成されています。ボキャブラリーは「name(名前)」のように情報を定義する値のことで、シンタックスはボキャブラリーを記述する形式のことです。
シンタックスに沿ってHTMLにボキャブラリーを記述することで、構造化データとしてリッチリザルトなどに反映されるようになります。
ここからはボキャブラリーとシンタックスについて具体的に解説していきます。
ボキャブラリーとは?
構造データの情報を定義する規格のようなものを「ボキャブラリー」と呼びます。ボキャブラリーはさらにいくつかの種類に分けられますが、現在Googleがサポートしているボキャブラリーの代表例が「schema.org」です。
schema.orgとは、Google・Yahoo!・Microsoftの大手検索エンジン会社が共同で管理しているボキャブラリーで、情報を定義する値は日々増え続けています。
たとえば会社名の「株式会社ヒトノテ」には「name」、所在地の「千代田区」には「address」というように定義することで、検索エンジンが情報の意味を理解できるようになります。
また、ボキャブラリーは階層構造になっており、人物を説明する「Person」では誕生日や所属団体、運営サイトなどの子項目も使用可能です。schema.orgでマークアップできる値はホームページに記載されており、人物に関わる値はこちらのページの一覧で確認できます。
シンタックスとは?
ボキャブラリーは情報を定義するものですが、ただ記載するだけでは検索エンジンが読み取ってくれません。適切に認識してもらうためには、「シンタックス(形式)」に沿った記述が必要です。
シンタックスは、HTMLにマークアップする際の仕様のことで、Googleは以下の3つをサポートしています。
- JSON-LD(推奨)
- Microdata
- RDFa
現在はGoogleが推奨しているJSON-LDを使用するケースが多く、以下のメリットがあります。
- HTMLのどこに記述しても問題ない
- 他のHTMLに影響を及ぼさない
- データをまとめて記述できるため、人間も把握しやすい
- 不可視データだけなら記述量が少ない
他のシンタックスは、HTMLで各情報に直接マークアップが必要です。一方でJSON-LDは、HTMLのどこに記述しても問題ありません。一般的にはhead要素内に記述するものの、サイト運営者が管理しやすい箇所への記述も可能です。
また、直接マークアップするシンタックスは、構造化データの値がどこにあるのか把握しにくいというデメリットがありました。しかしJSON-LDは、一箇所にまとめて記載できるため、HTMLの更新時などにも見直しやすいです。複数の担当者がいるメディアでも管理しやすく、引き継ぎもスムーズに行えます。
一方で、HTMLを編集する場合はそれに合わせてJSON-LDも修正する必要があります。HTMLと構造化データの内容が常に一致するようにメンテナンスしておきましょう。
構造化データをマークアップする方法
構造化データをマークアップする方法は、主に以下の2つです。
- HTMLに直接マークアップする
- Googleのウェブマスターツールを活用する
どちらにもメリットとデメリットがあるため、サイトのコンテンツや管理方法などによって選択しましょう。
ここからは構造化データをマークアップする2つの方法について詳しく解説します。具体例を用いてわかりやすく解説するので、どちらを選べば良いのかわからない方は参考にしてみてください。
HTMLに直接マークアップする
1つ目は、HTMLに直接マークアップする方法です。今回はボキャブラリー「schema.org」、シンタックス「JSON-LD」を用いて、以下の情報をマークアップする方法を紹介します。
▼株式会社ヒトノテの会社概要の例
<div>会社名:株式会社ヒトノテ</div>
<div>所在地:東京都千代田区西神田2-2-7 江口ビル401</div>
<div>TEL:03-6265-6636</div>
<div>設立:2017年4月</div>
<div>代表取締役:坪昌史</div>
<div>URL:https://hitonote.co.jp/wp2</div>このような記述方法では、システムは情報の内容を認識できません。順を追ってマークアップしていきましょう。
マークアップする要素を確認
まずは構造化データをマークアップできる要素を確認しましょう。マークアップできる値はschema.orgのホームページで確認できます。株式会社ヒトノテの会社概要の例であれば6項目すべてマークアップ可能です。
また、マークアップすることでリッチリザルトとして表示されるかどうかも確認しておきましょう。リッチリザルトは約30種類あり、Google検索セントラルにて確認できます。
今回の例では、問い合わせ先以外はマークアップしてもリッチリザルトが表示されません。しかし、表示されない項目のマークアップが無駄というわけではありません。構造化データの設定によって検索エンジンは情報の意味を理解しやすくなるので、間接的なSEO効果を得られる可能性があります。
あくまでもマークアップする要素の優先順位を決めるために確認しておきましょう。
実際にマークアップを行う
マークアップする箇所や該当するボキャブラリーを確認できたら、HTML内に記述していきましょう。今回の例をマークアップすると以下のような状態になります。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "株式会社ヒトノテ",
"founder": "坪昌史",
"foundingDate": "2017年4月",
"url": "https://hitonote.co.jp/wp2",
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+81-3-6265-6636",
"contactType": "customer support",
"areaServed": "JP"
},
"address": {
"@type": "PostalAddress",
"addressLocality": "千代田区, 東京",
"postalCode": "101-0065",
"streetAddress": "西神田2-2-7江口ビル401"
}
} </script>冒頭の「<script type=”application/ld+json”>」は「JSON-LDで記述します」という意味で、「”@context”: “http://schema.org”,」は「schema.orgで記述します」という意味です。
JSON-LDでは、「”キー名”:”値”」という形式で情報を記述します。たとえば「@type」は何について記述するのかを指定するもので、「Corporation」が続くことで会社についての記述であることを宣言できます。
また、その後に「”name”: “株式会社ヒトノテ”」を記述することで「会社の名前は株式会社ヒトノテ」だと表現可能です。
このようにマークアップすることで、会社概要を検索エンジンに認識してもらえるようになります。
構造化データマークアップ支援ツールを活用する
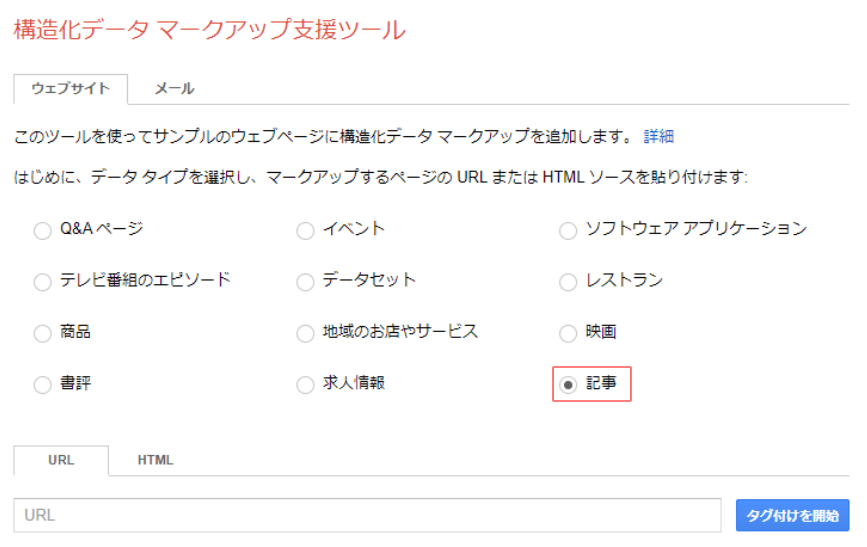
2つ目は、Googleのウェブマスターツールを活用する方法です。ウェブマスターツールには構造化データマークアップを支援するために開発した機能があり、HTMLに直接記述するよりも簡単に構造化データを活用できます。
「schema.orgやJSON-LDが理解できない」「日本語で使えるツールが良い」という場合には、構造化データマークアップ支援ツールの使用がおすすめです。
ここからは「【2023年版】SEO対策とは?仕組みや施策、進め方などを徹底解説」という記事を例に、マークアップの方法を解説します。
マークアップしたいデータタイプを選択
まずは構造化データマークアップ支援ツールにアクセスし、マークアップするページのデータタイプを選択しましょう。今回はコラム記事なので、「記事」を選択します。
Googleは1つのページに対するタイプは1つに統一することを推奨しているため、既存の構造化データがないことをあらかじめ確認しておきましょう。
マークアップしたいページのURLを入力しタグ付けを開始
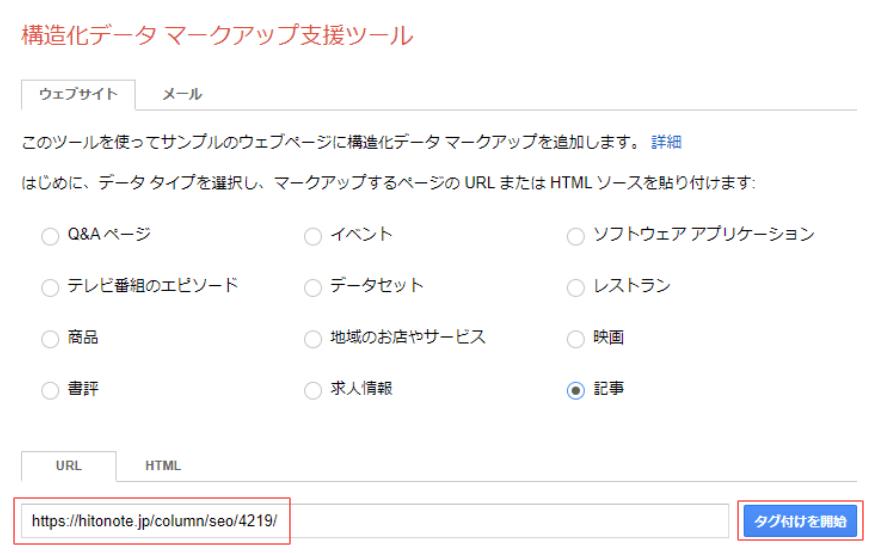
データタイプを選択したら、下部の空欄にURLあるいはHTMLを入力します。データタイプとURLによって次に表示される画面が変わるため、入力内容に間違いがないかどうか確認しましょう。
今回はコラム記事のURLをペーストして「タグ付けを開始」をクリックします。
実際にマークアップしていく
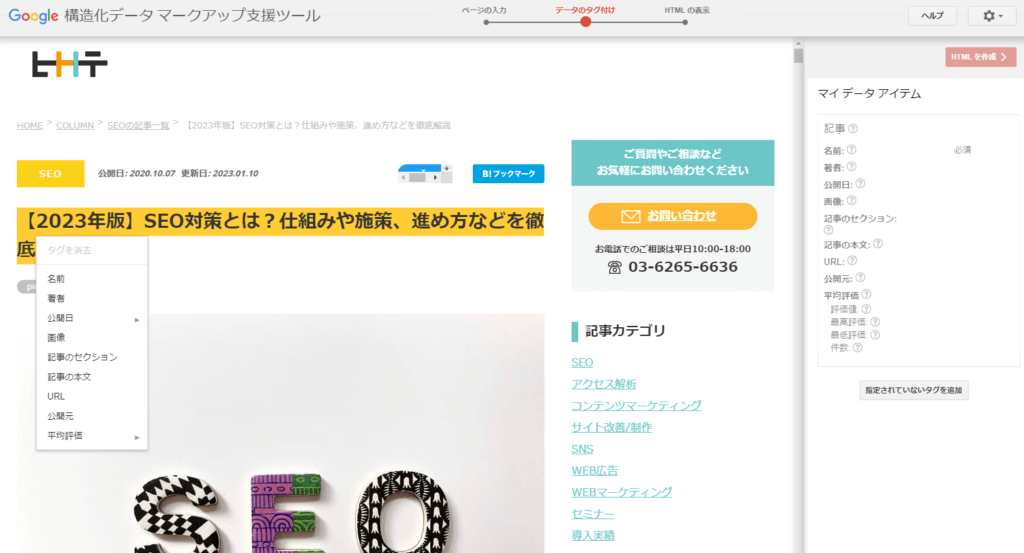
タグ付けは、ページが読み込まれたツール内の画面で行います。左側にページ、右側にはタグ付けできるデータアイテムが並んでいることを確認しましょう。今回はデータタイプ「記事」のため「著者・公開日・記事の本文」などの記事に関連するデータが並んでいます。
ページ内のテキストをクリック(ドラッグ)すると色が変わり、データアイテムの選択肢が表示されます。マークアップしたいテキストを選択してタグを選ぶことで、右側の一覧にテキストを反映可能です。同様の手順でマークアップしたい箇所を選択していきましょう。
HTMLを出力する
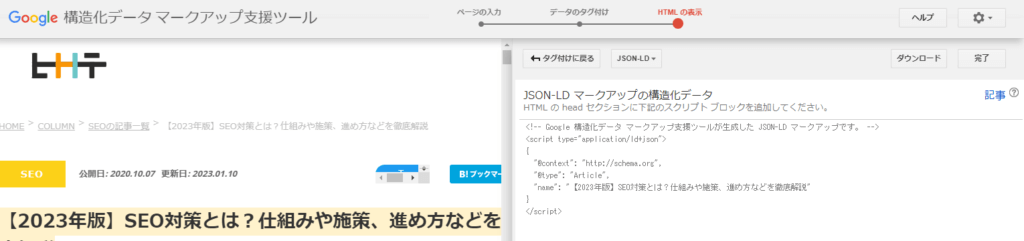
データの指定が完了したら画面右上の「HTMLを作成」をクリックしましょう。すると、構造化データがマークアップされたHTMLが表示されます。
出力したHTMLをサイトへ反映させる
支援ツールで出力されたHTMLをコピーして、記事のHTMLのheadセクションにペーストすればマークアップ完了です。
構造化データマークアップ支援ツールでのマークアップには多少の制限はあるものの、専門知識が必要という構造化データ活用のデメリットを克服できます。出力したHTMLは加筆修正できるので、ツールでHTMLの枠組みを作り、細部は直接編集するのもおすすめです。
テストツールの紹介
構造化データは実装して終わりではなく、きちんと反映されているかどうか確認する必要があります。また、HTMLの編集に伴うメンテナンスも欠かせません。そこで役に立つのがテストツールです。
リッチリザルト用の構造化データは「リッチリザルトテスト」、リッチリザルトに使われていない構造化データは「スキーママークアップ検証ツール」というテストツールを使うことで簡単に検証できます。
ここからは2つのテストツールについて詳しく解説します。
リッチリザルトテスト
リッチリザルトテストは、設定した構造化データが正しく反映されているかを確認するGoogleの公式ツールです。
URLあるいはHTMLを入力することで、どの項目が反映されているのか、検索結果でどのように表示されるのかを確認できます。「有効なアイテムを検出しました」や「このページはリッチリザルトの対象です」と表示されれば、構造化データは正しく反映されている証です。
また、構造化データに関する問題も自動で検出してくれるので、メンテナンスの手間も削減可能です。
スキーママークアップ検証ツール
スキーママークアップ検証ツールとは、Schema.orgを用いた構造化データを検証するテストツールです。過去に普及していた「構造化データテストツール」から Google 固有の検証が取り除かれ、新しいドメインでスキーママークアップ検証ツールとして公開されました。
リッチリザルトへの反映状況を確認するリッチリザルトテストに対し、スキーママークアップ検証ツールはSchema.orgによる構造化データのすべてを確認できます。RDFaやMicrodataにも対応しているので、幅広いサイトを分析可能です。
まとめ
構造化データは、検索エンジンが認識できる形式で記述されたデータのことで、セマンティックWebという考え方に基づいて生まれました。構造化データ自体にSEO効果はないものの、構造化データによるリッチリザルトなどのメリットがSEOに間接的な効果をもたらす可能性があります。
構造化データの設定は、HTMLに直接マークアップする方法とGoogleのウェブマスターツールを使用する方法があります。それらの方法で設定した後は、テストツールを用いて反映状況を確認しましょう。
執筆者:ヒトノート編集部
株式会社ヒトノテのオウンドメディア、WEBマーケティングの学習帳「ヒトノート -Hito note-」の編集部。

監修者:坪昌史
株式会社ヒトノテの代表取締役CEO。 エンジニアとしてキャリアスタートし、サイバーエージェントのSEO分析研究機関を経て、リクルートの横断マーケティング組織のマネージャー&全社SEO技術責任者を務める。その後、独立しSEOを中心としたクライアントの課題解決を行う。2017年、株式会社ヒトノテを創業し、様々な企業のウェブマーケティングの支援を行う。
おすすめの関連記事
 2020年12月24日 オウンドメディアの構築方法をわかりやすく解説! Posted in コンテンツマーケティング
2020年12月24日 オウンドメディアの構築方法をわかりやすく解説! Posted in コンテンツマーケティング 2020年1月9日 【一覧】Web広告の費用相場とは?費用の発生条件も解説 Posted in WEB広告
2020年1月9日 【一覧】Web広告の費用相場とは?費用の発生条件も解説 Posted in WEB広告 2021年4月30日 h1タグの正しい使い方とは?SEO効果や注意点を解説 Posted in SEO, コラム
2021年4月30日 h1タグの正しい使い方とは?SEO効果や注意点を解説 Posted in SEO, コラム 2023年12月14日 <株式会社成基様>社員かのような近い距離で徹底伴走~ホームページ経由の入塾数UP&マーケティングの内製化を実現~ Posted in 導入実績
2023年12月14日 <株式会社成基様>社員かのような近い距離で徹底伴走~ホームページ経由の入塾数UP&マーケティングの内製化を実現~ Posted in 導入実績 2021年1月8日 ロングテールSEOとは?コンテンツマーケティングでの活用法を解説! Posted in SEO
2021年1月8日 ロングテールSEOとは?コンテンツマーケティングでの活用法を解説! Posted in SEO 2022年12月9日 GA4でのパラメータ設定手順とは Posted in アクセス解析
2022年12月9日 GA4でのパラメータ設定手順とは Posted in アクセス解析 2020年9月6日 【比較】ワイヤーフレームツールおすすめ10選!種類や選び方も解説 Posted in サイト改善 / 制作
2020年9月6日 【比較】ワイヤーフレームツールおすすめ10選!種類や選び方も解説 Posted in サイト改善 / 制作 2020年2月4日 掲載落ちページのSEOベストプラクティス Posted in SEO
2020年2月4日 掲載落ちページのSEOベストプラクティス Posted in SEO
─ 記事カテゴリから探す ─

元リクルートのSEO責任者へ無料相談
人気記事ランキング
-

2024.05.30
キーワードマーケティングのやり方とは?SEOの効果が見込める手順を徹底解説
-

2024.05.27
SEOにおけるURL設計のベストプラクティス
-

2024.04.25
ページネーションのSEOにおけるベストプラクティス
-

2024.04.22
E-E-A-Tとは?Googleが評価するコンテンツの基準や対策を解説
-

2021.07.09
Webコンテンツにおける正しい引用の書き方をマスターしよう!
-

2021.12.06
レスポンシブデザインの最適ブレイクポイントとは?メディアクエリの書き方も解説
-

2021.12.22
【徹底比較】さくらのクラウドとAWSの特徴・機能・料金の違いを解説
-
2022.02.21
「note」のユーザー数や年齢層を徹底分析!【2022年版】
-

2022.07.05
WordPressで301リダイレクトを設定する方法とは?初心者でも可能








